

Analogique et numérique
L’être humain perçoit les images et les sons de manière analogique : aidés du cerveau, ses yeux enregistrent les variations de luminosité (luminance) et de couleurs (chrominance), tandis que son ouïe « décode » les modulations d’amplitude et de fréquences sonores. Le traitement numérique (Digital en anglais) des informations n’est qu’une étape intermédiaire permettant de les enregistrer, de les stocker et de les transmettre d’une façon plus économique. Le schéma de base de tout procédé numérique est donc :
- capture analogique
- conversion analogique/numérique (A/N)
- traitement, stockage, transmission des informations sous la forme numérique
- conversion numérique/analogique (N/A), permettant la visualisation et/ou l’audition.
Principe de la numérisation
Prenons l’exemple simple d’un signal audio numérique, tel le son stéréo Nicam qui accompagnait certaines émissions de télévision. Pour la numérisation de cassette vidéo il faut considérer deux facteurs dont dépend la qualité de la restitution sonore :
Échantillonnage. Le signal analogique est découpé en « tranches » de signaux binaires « 0 » et « 1 », à une certaine fréquence dite « d’échantillonnage ». Dans le cas du Nicam, celle-ci est de 32 kHz. Puisqu’il faut deux bits (« 1 » et « 0 ») pour caractériser un seul échantillon, la fréquence maximale du signal numérisé (sa « bande passante » si vous préférez) correspond au mieux à la moitié de la fréquence d’échantillonnage. On a ainsi une fréquence audio maximale de 16 kHz environ pour le Nicam, alors qu’elle atteint 22 kHz environ pour le CD audio, échantillonné à 44 kHz.
On attribue à chaque échantillon la valeur binaire correspondant à l’amplitude du signal analogique d’origine
Quantification. L’opération consiste à attribuer un plus ou moins grand nombre de niveaux d’amplitude aux échantillons binaires successifs. Plus il y a de niveaux, plus la restitution est à la fois détaillée (résolution) et dynamique (rapport signal/bruit plus élevé). Le nombre de niveaux est égal à 2 puissance n bits (2′). Par exemple, une quantification 8 bits signifie donc 28 niveaux, avec une résolution de 256 niveaux. On a de même 2’4 = 16 384 niveaux pour le Nicam quantifié 14 bits, ou encore 2’6 = 65 536 niveaux dans le cas du CD audio, quantifié 16 bits.
Et la vidéo ?
Le principe de numérisation vidéo est identique, mais avec des ordres de grandeur très supérieurs, les fréquences à traiter étant 250 à 300 fois plus élevées. En numérique sans compression, il faudrait traiter, stocker, décoder N/A (numérique/analogique), puis injecter dans le téléviseur/moniteur vidéo autant d’informations élémentaires que cette image animée en comporte par seconde (par exemple 165 Mbits/s en télévision broadcast).
Quatre facteurs déterminants
Fréquence image
En Europe — système Pal/Secam, 625 lignes/50 Hz — la fréquence image de la vidéo est de 25 images par seconde. Mais chaque image est en fait constituée de deux trames (l’une de lignes impaires, l’autre de lignes paires) qui s’affichent séquentiellement sur l’écran du moniteur/téléviseur : la trame des lignes impaires, puis (dans les espaces laissés libres par celle ci) la trame des lignes paires. C’est « la vidéo entrelacée 2:1 ». L’ordinateur opère très différemment, en rafraîchissant l’écran par « balayage progressif », dit aussi « non-entrelacé ». Les images complètes s’affichent du haut vers le bas de l’écran à la fréquence de 30 im/s.
Résolution couleur
Ce deuxième facteur bien plus complexe se réfère au nombre de couleurs qu’on peut (théoriquement) afficher simultanément à l’écran. L’ordinateur traite habituellement la couleur dans un format composantes RVB (rouge, vert, bleu), alors que la vidéo broadcast utilise différents formats composite ou composantes. L’un des plus courants pour la capture des images est un format analogique composantes différentiel couleur nommé « YUV ». Sans détailler comment la vidéo numérique enregistre les différences de couleurs (elles sont spécifiées par groupes de quatre pixels), il n’y a pas de corrélation directe entre le RVB de l’ordinateur et le YUV, bien qu’ils permettent tous deux de spécifier la « profondeur couleur » (nombre maximum de couleurs restituables). Avec l’ordinateur en mode RVB, les résolutions proposées sont de 8 bits par pixel (256 couleurs), 16 bits/pixel (65 536 couleurs) ou 24 bits/pixel (16,7 millions de couleurs). En vidéo composantes YUV, elles sont de 7 bits en 4:1:1 ou 4:2:2 (2 millions de couleurs environ) et de 8 bits en 4:4:4 (16 millions de couleurs environ).
Résolution spatiale
Ce facteur qualifie le « format » de l’image. Les écrans d’ordinateur PC et Mac de base ayant une résolution de 640 x 480 (304 200 pixels), certains pensent à tort qu’il s’agit du standard vidéo. Cependant, comme entre le RVB et le YUV, il n’y a pas de corrélation directe entre la résolution d’un moniteur vidéo et celle d’un écran ordinateur restituant de la vidéo animée : le premier affiche les images en plein écran, alors que l’ordinateur les visualise à l’intérieur d’un cadre noir ou « fenêtre image » ( Windows).
En télévision Pal ou Secam, la résolution standard est de 768 x 576 (442 368 pixels).
Qualité d’image
Ce dernier facteur est le plus important. Il s’agit d’obtenir une qualité vidéo acceptable, compte tenu de l’application que l’on veut en faire. Pour certaines applications (visiophonie, interphonie, etc.), la vidéo sur un quart d’écran ou moins, à 15 im/s et avec une résolution couleur de 8 bits/pixel peut suffire. La télévision broadcast sans perte exige en revanche une résolution plein écran (1920 × 1080), à 25 im/s, avec une profondeur couleur de 24 bits/pixel (16,7 millions de couleurs).
Numériser, oui, mais…
La vidéo numérique implique la manipulation d’une masse énorme d’informations, sous la forme d’un flux de données numériques, véhiculées en série ou en parallèle. La vitesse de transmission du flux de données porte le nom de débit numérique, généralement exprimé en nombre de bits par seconde. La qualité des signaux vidéo transmis est d’autant plus grande que le débit numérique est plus élevé (voir encadré ci-dessous).
Pourquoi utilise-t-on la compression numérique ?
Prenons 2 exemples :
- Tel mode de transmission d’images vidéo par voie téléphonique se fait à 360 pixels par ligne, 288 lignes par image vidéo, 12 bits/pixel et une fréquence de 10 im/s. Le débit numérique est donc : 360 x 288 x 12 x 10 = 12,44 Mbit/s (millions de bits par seconde).
- Un signal vidéo de qualité professionnelle, tel le signal composantes 4:2:2 requiert un débit numérique bien plus élevé. En système Pal : 1920 pixels par ligne, 1080 lignes par image, 16 bits/pixel, 50 im/s (1080p), soit un débit de : 1920 x 1080 x 16 x 50 = 1,65 Gbit/s. (207 Mo/sec.)
- Interface SATA III : 600 Mo/s
- Interface USB 3.1 : 10 Gb/sec.
- Débit disque dur d’un ordinateur PC ou Mac : 150 Mo/s environ avec un disque dur classique.
- CD-Rom (débit de transfert) : 1,2 Mbit/s.
- DVD-Rom (débit de transfert) : 200 Mb/sec environ. (×20)
On voit qu’en pratique courante, l’exploitation de la vidéo numérique serait impossible sans compression du signal à une valeur compatible avec la capacité nominale des réseaux de transmission et avec le débit numérique maximal autorisé par les équipements destination.
Méthodes de compression
Elles mettent en œuvre des algorithmes mathématiques complexes qui réduisent (ou compriment) les données vidéo en éliminant, et/ou en regroupant, et/ou en faisant la moyenne (en interpolant) les données semblables (« redondances ») détectées dans le signal vidéo. Le seul standard de compression vidéo animée actuellement accepté sur le plan international est le MPEG. MPEG est l’acronyme de Motion Picture Expert Group, un groupe de travail réunissant divers organismes internationaux, ainsi que les principaux acteurs des industries de la vidéo et de l’informatique.
Motion JPEG & MPEG : les différences
Le Motion JPEG (mjpeg) utilise la méthode « intraframe » qui comprime et mémorise chaque image vidéo complète sous la forme d’une image.
Le MPEG utilise au contraire la méthode « interframe », basée sur l’idée que dans une scène d’action enregistrée en vidéo, certains éléments de la scène — tel le décor — ne se déplacent pas d’une image à la suivante (redondance spatiale), ou bien qu’ils se déplacent à l’intérieur du cadre sans changer de forme — un ballon de foot, par exemple — (redondance temporelle).
En mode MPEG, on débute une séquence de compression par la création d’une image de référence, appelée « I » pour « Intraframe ». Puis, chaque image vidéo suivante est comparée avec l’image précédente et avec celle qui suit, et l’on se contente de mémoriser les différences spatiales et temporelles entre les images successives, ce qui réduit considérablement le volume d’informations à stocker.
Le processus d’interpolation est réitéré pour un petit nombre d’images (habituellement de 10 à 15), puis l’on crée une nouvelle image « I » à partir de laquelle on compresse la séquence suivante, et ainsi de suite. Facteurs pris en compte par la compression
Le but de la compression vidéo est donc de réduire massivement le volume de données à stocker dans un fichier numérique, en perdant le moins possible de la qualité vidéo originale. La compression des données numériques implique la prise en compte d’au moins six facteurs, en particulier pour les applications sur ordinateur PC.
Temps réel ou temps non-réel
Dans le domaine de la compression, « temps réel » dit bien ce qu’il veut dire. Certains systèmes de compression capturent, compressent sur le disque, décompressent et relisent la vidéo (à 30 im/s) en temps réel, sans aucun retard : c’est le cas du CD-Rom, par exemple. D’autres, ne capturent que quelques-unes des trente images/seconde du signal d’origine et/ou ne peuvent restituer que certaines d’entre elles. En vidéo, une fréquence image trop faible est le défaut le plus gênant : à moins de 25 im/s, l’image « scintille ».
De plus, la resynchronisation de l’image et du son devient impossible, cela car les images manquantes contenaient des données de synchronisation audio indispensables.
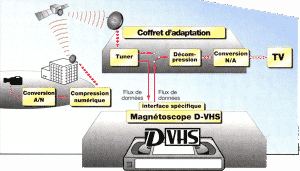
Principe du système JVC d’enregistrement numérique D-VHS. Le magnétoscope D-VHS (compatible VHS/S-VHS) enregistre des signaux numériques déjà compressés en mode MPEG-2. L’entrée du signal audio/vidéo composite dans le téléviseur ne peut se faire qu’après décompression et conversion numérique/analogique du signal enregistré sur la cassette D-VHS.
Symétrie ou asymétrie
Cette notion fait référence à la manière dont les images vidéo sont compressées et décompressées. La compression symétrique implique qu’après stockage, la restitution avec décompression en lecture se fait selon les mêmes paramètres que la compression à l’enregistrement. En d’autres termes, si vous pouvez relire une séquence vidéo de format 640 x 480 à 30 im/s, c’est bien que vous l’avez capturée, compressée et mémorisée à la même cadence. La compression est dite asymétrique lorsqu’il faut plus de temps pour compresser et stocker les données que pour les lire. Par exemple, un taux d’asymétrie de 15:1 signifie qu’il faut environ 15 minutes pour compresser une minute de vidéo.
Taux de compression
Le taux de compression (à ne pas confondre avec le taux d’asymétrie) indique de combien le volume de données vidéo compressées est plus « petit » que celui des données de la vidéo d’origine. D’une manière générale, la qualité vidéo finale décroît proportionnellement au taux de compression. En mode MPEG, un taux de compression de 200:1 est chose commune, la qualité image restant « acceptable ». Le mode Motion JPEG utilise des taux de compression plus faibles, compris entre 15:1 et 80:1, bien que le taux de 20:1 soit le taux maximum conservant la qualité originale des images.
Compression sans perte ou avec perte
Le facteur de perte (Loss Factor) détermine empiriquement s’il y a eu perte de qualité entre l’image originale et après sa compression, puis à sa décompression en lecture. A priori, le facteur de perte est d’autant plus élevé que le taux de compression est grand. Même si la perte de qualité est à peine sensible, la méthode est considérée comme Lossy (avec perte). Dans l’état actuel de la technologie, les seuls algorithmes « sans perte » (Lossless) sont ceux utilisés pour la compression des images fixes (photo numérique). Le taux de compression maximal sans aucune perte ne dépasse guère un facteur de 2:1. C’est pourquoi l’affichage écran ou l’impression d’une photo numérique haute résolution demande toujours plusieurs secondes ou minutes.
Et le DV ?
Nous nous penchons ici sur les applications de montage informatique et de diffusion du numérique. Nous ne nous étendons pas sur le DV (Digital Video). On peut cependant rappeler, en regard des points soulevés ici, que le DV est évidemment en temps réel, plein écran, et qu’il produit 25 images/seconde (30 en NTSC). La compression est symétrique réversible. En clair, il n’existe pas de différence entre la première et la deuxième génération (la source et la copie). Le système peut être considéré comme sans perte, dans la mesure où le facteur de compression est limité à cinq et qu’aucune dégradation n’est sensible à l’œil du spectateur.
Enfin, le DV utilise la méthode intraframe, toutes les images ont le même poids et par conséquent, sont parfaitement utilisables au montage.
Interframe et Intraframe
Ces notions, impossibles à expliquer en quelques phrases, constituent la différence fondamentale entre les deux grands standards de compression que sont le MPEG et le Motion JPEG (voir ci-dessous).
Contrôle du débit numérique
Dernier facteur déterminant qu’il faut prendre en compte en compression vidéo, le contrôle du débit numérique : un point particulièrement important compte tenu du débit de transfert limité du système ordinateur. Le système de compression doit permettre à l’utilisateur de stipuler au matériel et au logiciel quels sont les paramètres les plus importants à contrôler.
Pour certaines applications, la fréquence image est de première importance, alors que le format de l’image ne l’est pas. Pour d’autres, il n’est pas gênant d’accepter une fréquence image inférieure à 15 i/s, alors que les images individuelles plein écran doivent être de la meilleure qualité.
Vidéo animée : MPEG ou MJPEG
Compte tenu du grand nombre de facteurs concernés et des divers constructeurs proposant des solutions antagonistes, il est sage de s’en tenir aux grands standards : s’ils ne garantissent pas « la meilleure solution », ils ont le mérite et de bonnes raisons d’exister. Le MPEG n’est pas une norme, mais il est actuellement bien accepté et très utilisé sur le plan international. Il ne cherche pas à privilégier tel matériel ou tel format vidéo. C’est un format « ouvert », c’est-à-dire pouvant être mis en œuvre par tous ceux — constructeurs ou utilisateurs — qui le désirent. Il en existe d’ailleurs plusieurs versions (MPEG-1, MPEG-2, MPEG-3, MPEG-4) spécifiquement adaptées aux divers problèmes à résoudre. Le Motion JPEG prévaut en revanche dans d’autres domaines d’application, dont le fameux montage vidéo numérique non linéaire utilisant des « imagettes »(montage virtuel).
Conclusion
Elle ne peut être que très provisoire. D’autres modes de compression se développeront inexorablement dans les prochaines années. Ils feront appel à de nouveaux algorithmes plus évolués et bénéficiant de microprocesseurs offrant une plus grande puissance de calcul. La compression « fractale »en fait sans doute partie.
Avantages et inconvénients du MPEG et du MJPEG
| MPEG | MJPEG | |
| Taux de Compression | Elevé (200:1) | Faible (20:1) |
| Résolution Maximum | Faible (720×576 MPEG2) – Elevée (4K et plus) | Elevée (4K et plus) |
| Qualité Vidéo | En fonction du taux de compression | Haute Qualité |
| Volume du Fichier | Faible (par rapport au mjpeg) | Très important |
| Accès dans le Fichier | Lent et difficile | Rapide et facile |
| Application Préférentielles | Blu-Ray, TVCF*, transmission numérique. | Montage vidéo, photo numérique. |
| * TVCF = Télévision en Circuit Fermé |
CV 89